

はじめに
こんにちは、サービス戦略課の大町です。
サービス戦略課では LANSCOPE エンドポイントマネージャー クラウド版の技術的負債解消やフローの自動化など、開発者の生産性向上のためのサービス改善に日々取り組んでいます。
今回は、 AWS Step Functions の Distributed Map を使って並列実行時のクォータ制限を解消した方法についてご紹介します。
AWS Step Functions とは
Step Functions は、複数の AWS サービスを組み合わせて実行するワークフローを簡単に作成・管理できるサービスです。
Lambda や SNS 、ECS などの AWS リソースをステートマシンと呼ばれるワークフローに組み込むことができます。
また、Step Functions は前のステップから JSON 配列を受け取ることで並列実行が可能となり、複数のタスクを同時に実行することができます。
クォータ制限に直面した話
弊社のとある社内ツールでは、 Step Functions の並列実行を使用してデータ集計にかかる時間を短縮しています。
しかし、集計対象のデータが増加傾向にあったため、同ツールの運用開始から 1 年ほど経過したタイミングで以下の課題に直面しました。
課題① ペイロードサイズが 256 KB を超えてしまった
2024 年 3 月現在、Step Functions には以下のようなクォータ制限が設けられています。
| 制限 | 説明 |
|---|---|
| タスク、状態、実行の最大の入力または出力サイズ | UTF-8 でエンコードされた文字列としての 256 KB のデータ。このクォータは、タスクのスケジュール、状態の入力、または実行の開始時に、タスク (アクティビティ、Lambda 関数、または統合サービス)、状態または実行出力、入力データに影響します。 |
課題発生時、同ツールの並列実行数は 3,000 近くまで増加していました。
並列実行数の増加によってステップ間で受け渡す JSON 配列のサイズが上記の制限を超えてしまい、以下のエラーが発生しました。
The state/task 'lambda' returned a result with a size exceeding the maximum number of bytes service limit.
課題② イベント数が 25,000 件を超えそうになった
2024 年 3 月現在、 Step Functions には以下のようなクォータ制限が設けられています。
| 制限 | 説明 |
|---|---|
| 実行履歴の最大サイズ | 1 つのステートマシンの実行履歴の 25,000 件のイベント。実行履歴がこのクォータに達すると実行は失敗します。 |
前述の通り、ツールの並列実行数が増加していたため 1 実行あたりのイベント数が 24,000 件近くまで達してしまい、上記の制限が懸念される状況になりました。
Distributed Map で解決する
タイトルの通り、これらの課題を Distributed Map を使って解決します。
Distributed Map とは
Distributed Map は Step Functions の機能の一つで、通常では困難な大規模な並列ワークロードを処理できる機能です。
通常の並列実行(以下 Map ステートという)と Distributed Map の主な違いは以下になります。
| 制限 | Mapステート | Distributed Map |
|---|---|---|
| 最大同時実行数 | 最大 40 回の反復を可能な限り同時に実行できます。 | 子ワークフローを最大 10,000 回並列で実行して、数百万件のデータ項目を一度に処理できます。 |
| 入力の最大サイズ | UTF-8 でエンコードされた文字列としての 256 KB のデータ。 | Amazon S3 データソースから直接入力を読み取ることができるため、ペイロードサイズの制限を解決できます。 |
| 実行履歴の最大サイズ | 実行イベント履歴に 25,000 エントリという制限を適用します。 | 子ワークフローの実行が親ワークフローの実行履歴とは別の独自の実行履歴を保持するため、実行履歴の制限を解決することもできます。 |
課題だったクォータ制限を解消できるだけではなく、最大同時実行数も大幅に増加するため、大量のデータを効率的に処理できるようになります。
Distributed Map の詳細については下記URLをご参照ください。 aws.amazon.com
Distributed Map を使うと本当に課題を解決できるのか、実際に検証してみます。
変更前
CloudFormation テンプレート
以下は Distributed Map を適用する前の CloudFormation テンプレートです。
※今回の検証用に作成した構成であり、細かい部分は省略しています。
Resources: SfnTestStateBefore: Type: AWS::StepFunctions::StateMachine Properties: RoleArn: ${実行ロールのARN} StateMachineName: "sfn-test-state-before" Definition: StartAt: LambdaInvoke1 States: LambdaInvoke1: Type: Task Resource: arn:aws:states:::lambda:invoke OutputPath: $.Payload Parameters: Payload.$: $ FunctionName: ${1つ目のLambdaのARN} Retry: - ErrorEquals: - Lambda.ServiceException - Lambda.AWSLambdaException - Lambda.SdkClientException - Lambda.TooManyRequestsException IntervalSeconds: 1 MaxAttempts: 3 BackoffRate: 2 Next: Map Map: Type: Map ItemProcessor: ProcessorConfig: Mode: INLINE StartAt: LambdaInvoke2 States: LambdaInvoke2: Type: Task Resource: arn:aws:states:::lambda:invoke OutputPath: $.Payload Parameters: Payload.$: $ FunctionName: ${2つ目のLambdaのARN} Retry: - ErrorEquals: - Lambda.ServiceException - Lambda.AWSLambdaException - Lambda.SdkClientException - Lambda.TooManyRequestsException IntervalSeconds: 1 MaxAttempts: 3 BackoffRate: 2 End: true MaxConcurrency: 40 End: true
図に表すと以下のような構成になります。
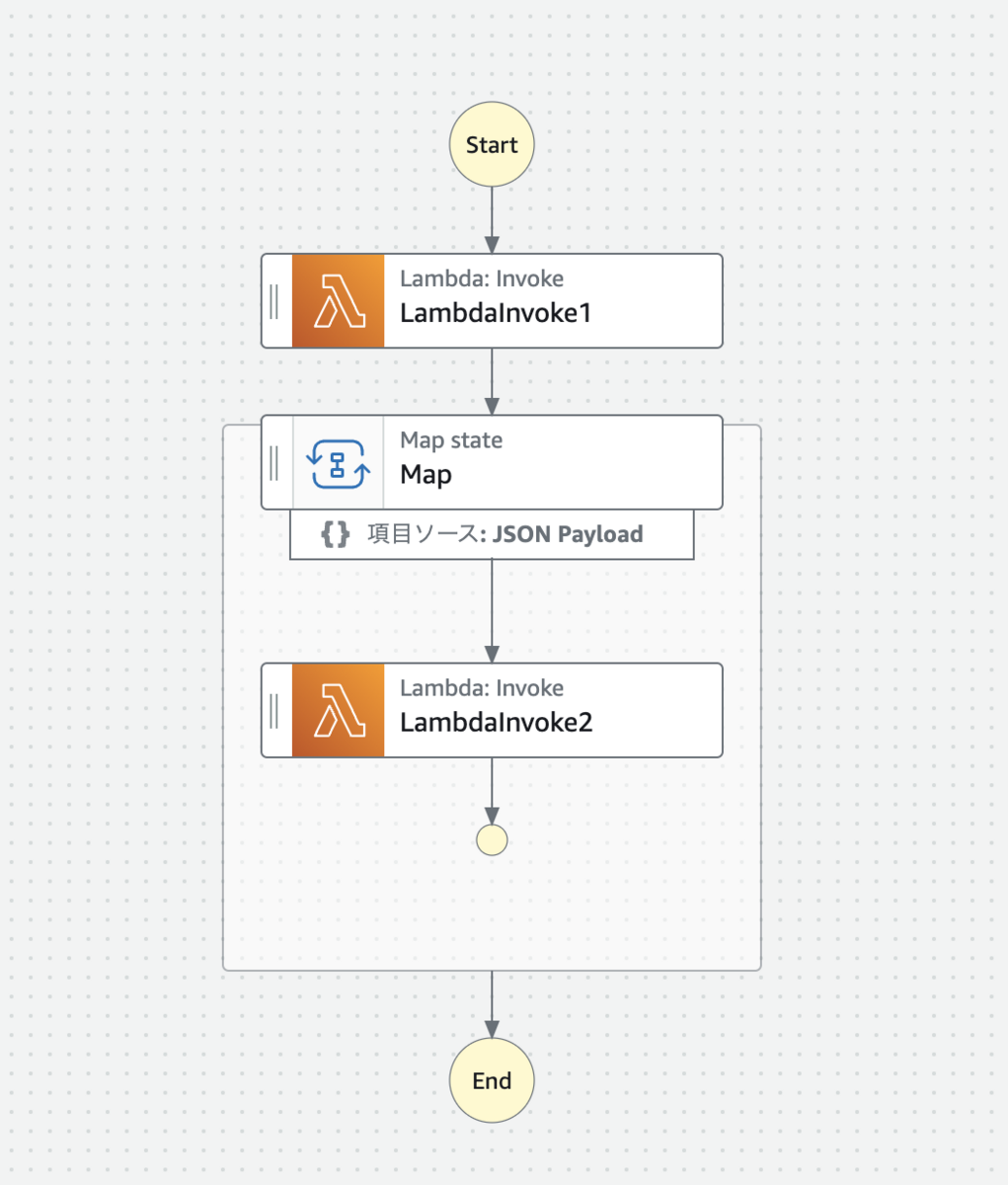
1 つ目の Lambda で配列を出力し、その配列を入力として 2 つ目の Lambda を並列実行させています。
実行結果
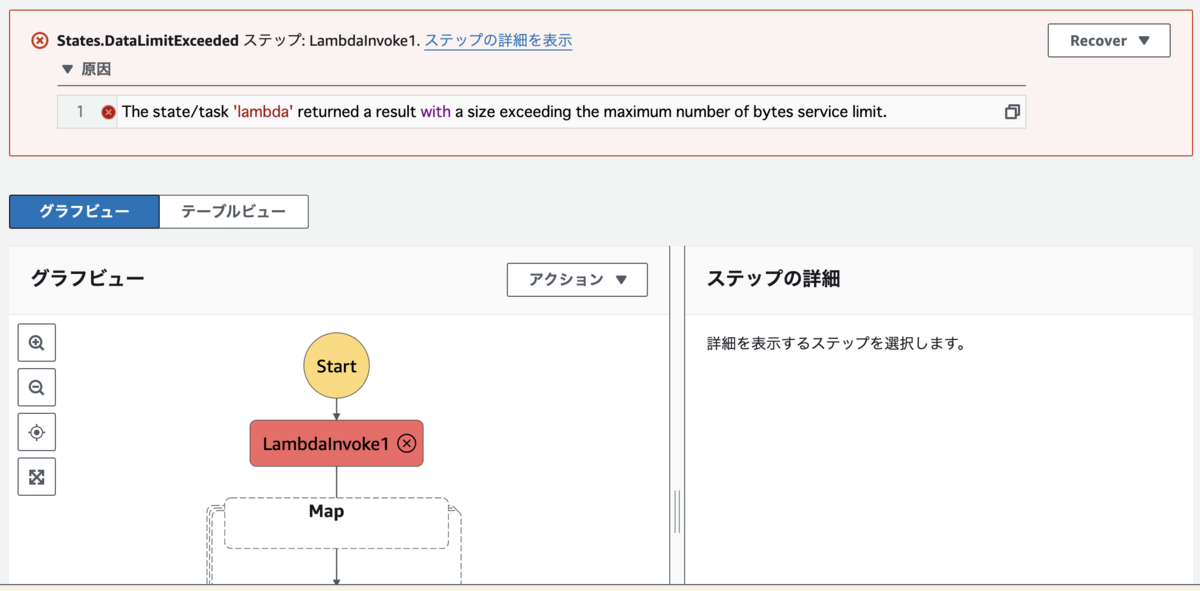
検証のために配列を加工し、意図的にクォータ制限を超えた状態にしてみました。
以下は入力の最大サイズ (256 KB) を超えたためエラーが発生しています。
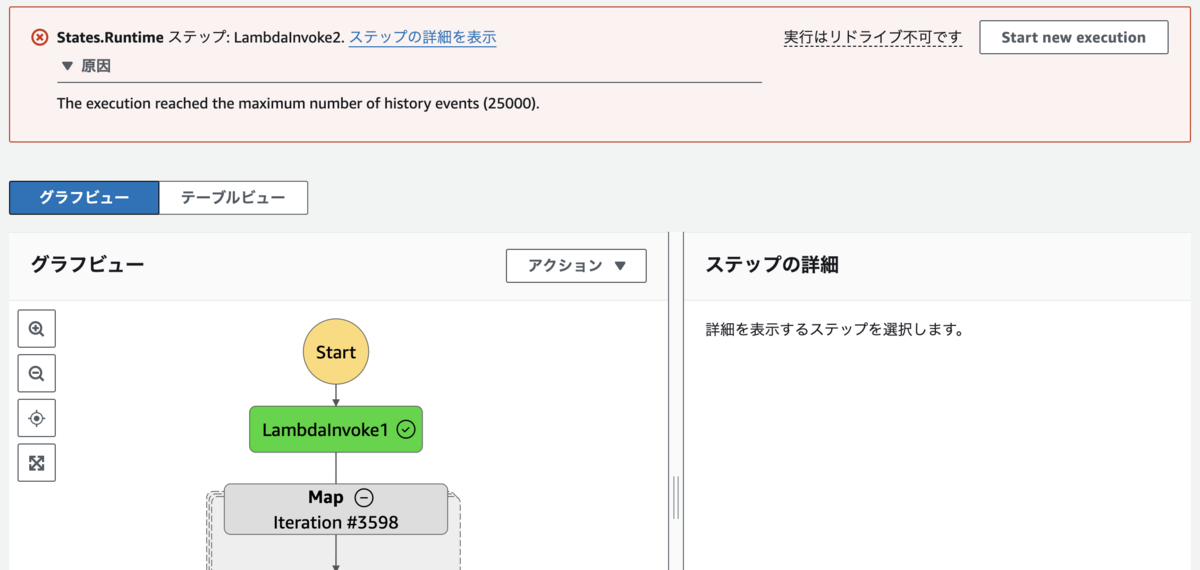
実行履歴の最大サイズ (25,000 エントリ) を超えた状態も再現しました。
変更後
CloudFormation テンプレート
以下は Distributed Map を適用した CloudFormation テンプレートです。
Resources: SfnTestStateAfter: Type: AWS::StepFunctions::StateMachine Properties: RoleArn: ${実行ロールのARN} StateMachineName: "sfn-test-state-after" Definition: StartAt: LambdaInvoke1 States: LambdaInvoke1: Type: Task Resource: arn:aws:states:::lambda:invoke OutputPath: $.Payload Parameters: Payload.$: $ FunctionName: ${1つ目のLambdaのARN} Retry: - ErrorEquals: - Lambda.ServiceException - Lambda.AWSLambdaException - Lambda.SdkClientException - Lambda.TooManyRequestsException IntervalSeconds: 1 MaxAttempts: 3 BackoffRate: 2 Next: Map Map: Type: Map ItemReader: Resource: arn:aws:states:::s3:listObjectsV2 Parameters: Bucket: ${S3のARN} Prefix: ${ディレクトリのパス} ItemProcessor: ProcessorConfig: Mode: DISTRIBUTED ExecutionType: STANDARD StartAt: LambdaInvoke2 States: LambdaInvoke2: Type: Task Resource: arn:aws:states:::lambda:invoke OutputPath: $.Payload Parameters: Payload.$: $ FunctionName: ${2つ目のLambdaのARN} Retry: - ErrorEquals: - Lambda.ServiceException - Lambda.AWSLambdaException - Lambda.SdkClientException - Lambda.TooManyRequestsException IntervalSeconds: 1 MaxAttempts: 3 BackoffRate: 2 End: true MaxConcurrency: 40 End: true
図に表すと以下のような構成になります。
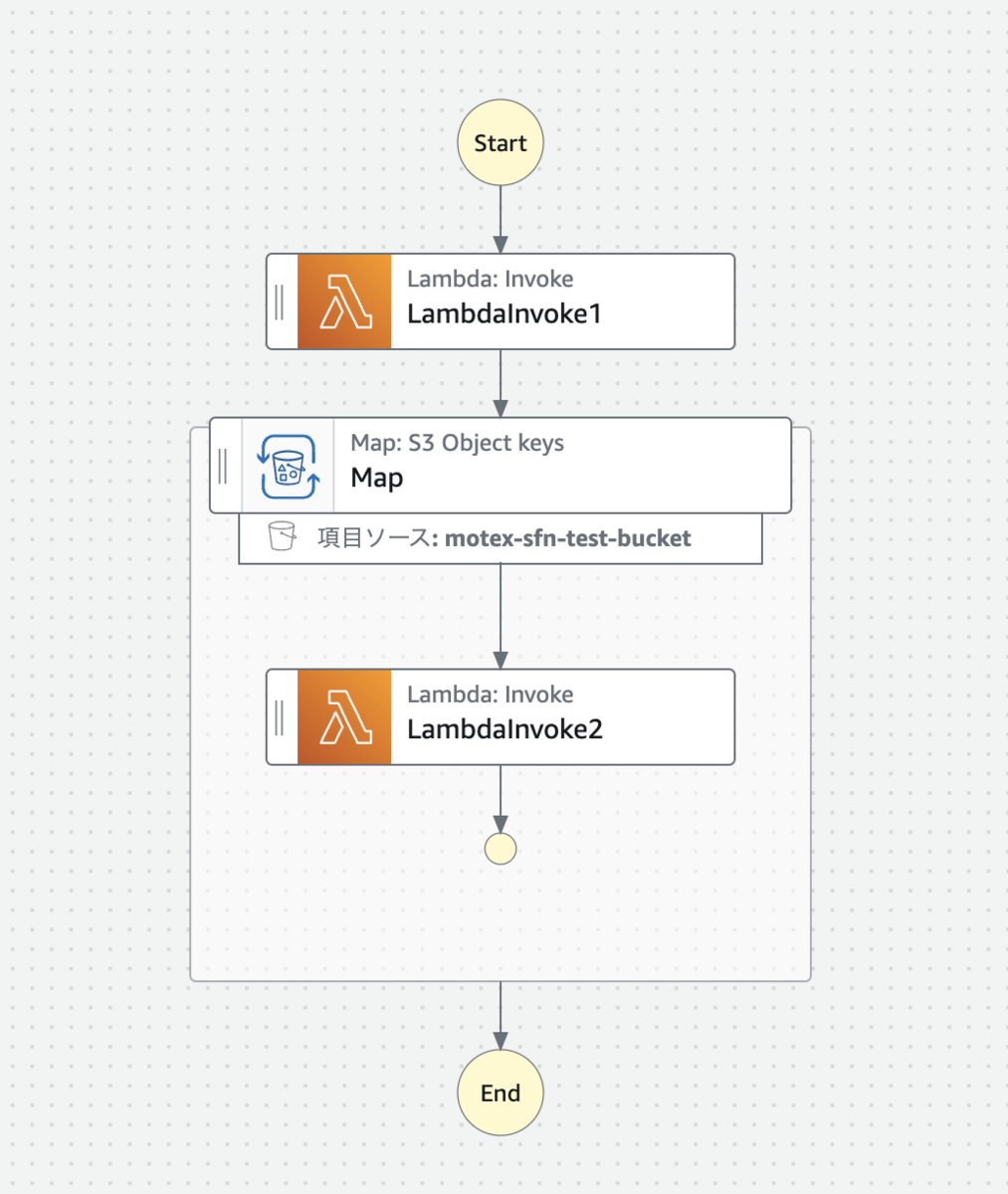
主な変更点は以下の 2 つです。
変更点① Distributed Map を適用する
適用方法は簡単で、 ProcessorConfig の mode を DISTRIBUTED に変更するだけです。
ItemProcessor: ProcessorConfig: Mode: DISTRIBUTED ExecutionType: STANDARD
Map ステートとは異なり、 ExecutionType の指定が必須になる点だけご注意ください。
変更点② 入力の受け渡し方を JSON 配列から Amazon S3 データソースに変更する
Map ステートでは配列を直接渡す形で並列実行の入力を定義していました。
しかし、そのままでは入力の最大サイズの制限に抵触してしまうため、 ItemReader を追加して S3 のバケット名・プレフィックスを定義する形に変更します。
ItemReader: Resource: arn:aws:states:::s3:listObjectsV2 Parameters: Bucket: ${S3のARN} Prefix: ${ディレクトリのパス}
1 つ目の Lambda は、配列の中身を JSON ファイルなどの形式に変換し、 S3 バケット内の特定のディレクトリにアップロードします。
Distributed Map 側は、指定されたディレクトリにあるオブジェクトをリストアップし、それらを入力として受け取ります。
実行結果
変更前と同様に、配列を加工して Map ステートのクォータ制限を超えた状態で実行してみます。
以下の通り、無事に処理が成功しました。
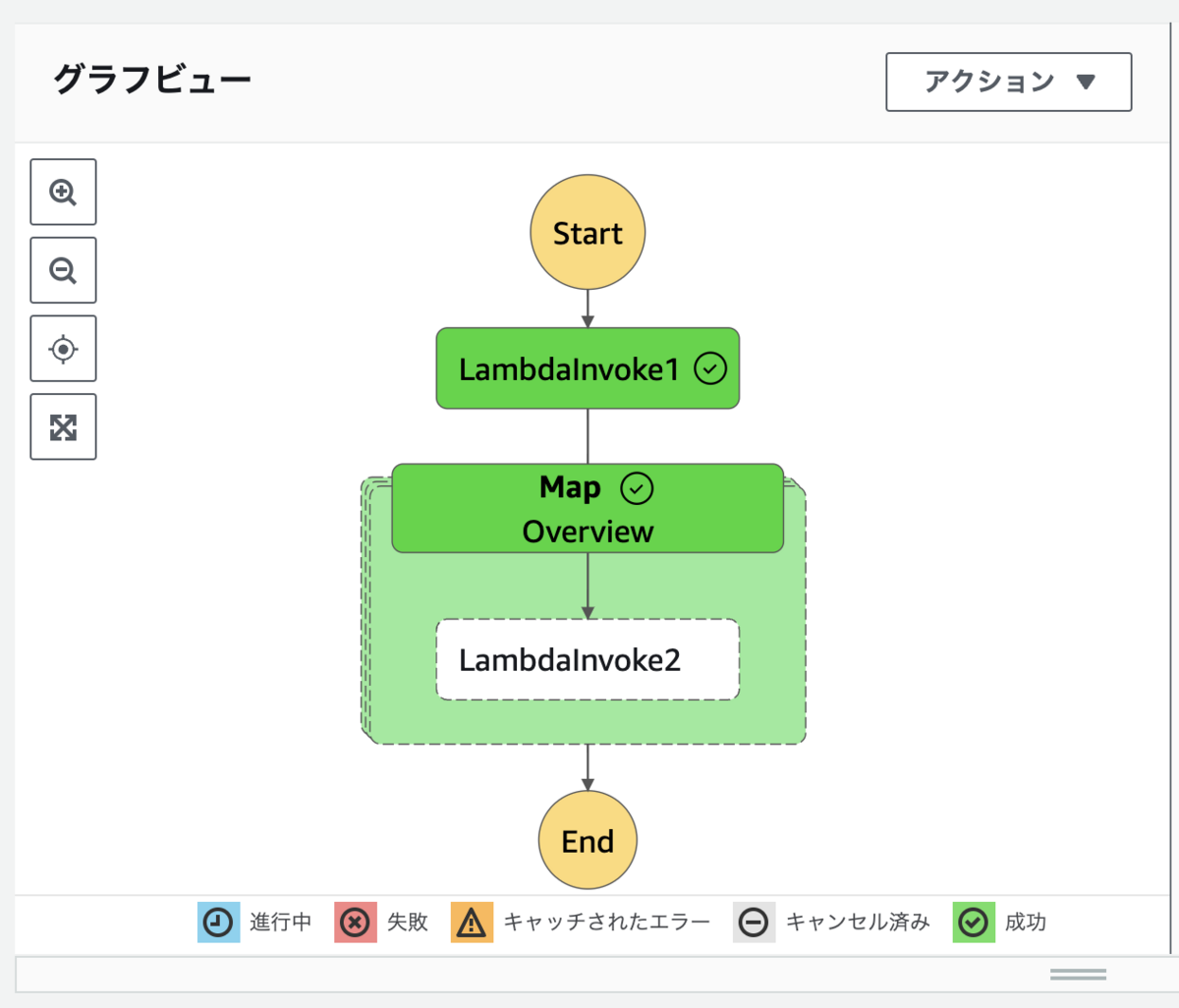
配列ではなく S3 のオブジェクト情報を渡したため、入力の最大サイズ制限を解消できました。
また、以下のように並列実行の内容は子ワークフローに分散されているため、実行履歴のサイズがクォータ制限を大きく下回りました。
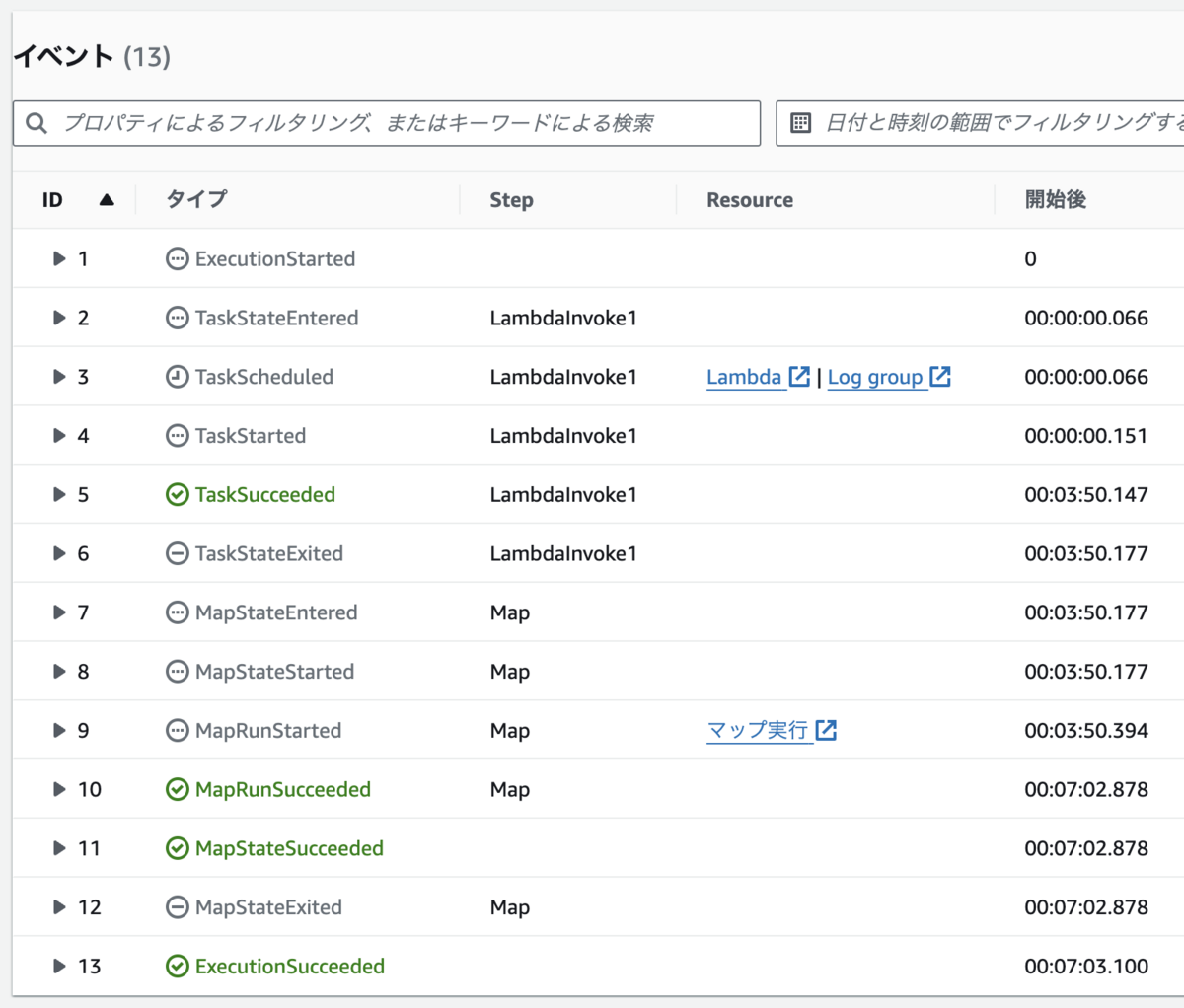
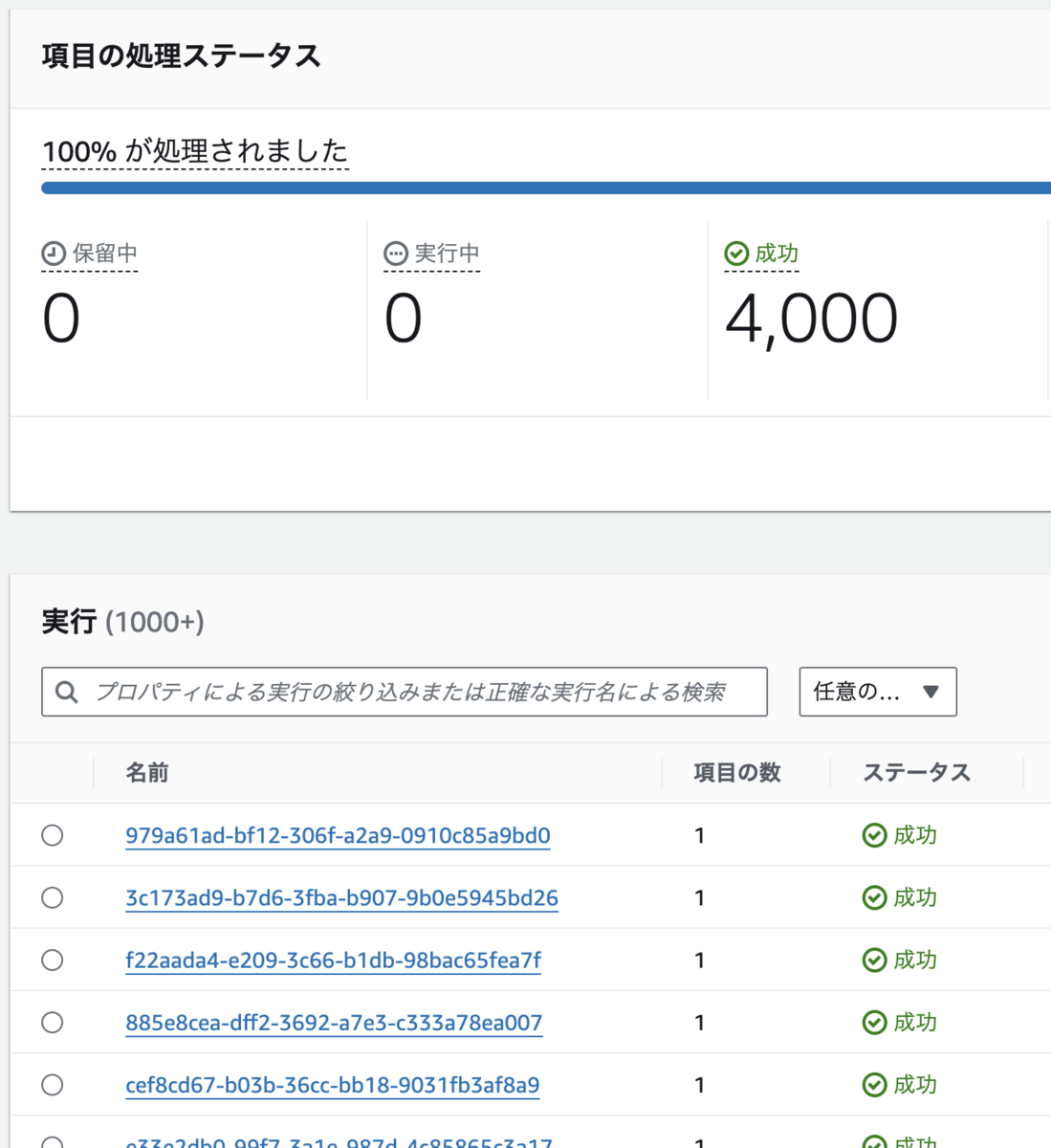
検証まとめ
Distributed Map の適用により、課題となっていたクォータ制限を解消することができました。
大規模な並列処理を簡単に実装できるため、時間がかかる重いバッチ処理などを改善したい場合に有効な手段だと思います。
注意点
Distributed Map で緩和される制限はあくまで Step Functions 上だけのものになります。
呼び出し先のサービスの制限を誤って超えてしまわないようご注意ください。
おわりに
AWS Step Functions の Distributed Map を使って、並列実行時のクォータ制限を解消した方法をご紹介しました。
ここまでお読みいただき、誠にありがとうございます。
本内容がお役に立てれば幸いです。