

はじめに
こんにちは、LANSCOPE セキュリティオーディター開発チームの宮﨑です。
LANSCOPE セキュリティオーディターでは、アプリケーションログなどの集約、閲覧にElastic Stackを活用しています。
今回は、Elasticsearchのバージョン8.11で追加されたElasticsearch Query Language (ES|QL)を活用して、nginxのログの集計を行いました。 実際に行った方法についてご紹介します。
本番環境では使用しないでくださいとの警告がドキュメントに記載されています。
ES|QLとは
ES|QLは、Elastic バージョン8.11からテクニカルプレビューとしてリリースされました。
ドキュメントでは、以下のように説明されています。
The Elasticsearch Query Language (ES|QL) provides a powerful way to filter, transform, and analyze data stored in Elasticsearch, and in the future in other runtimes. It is designed to be easy to learn and use, by end users, SRE teams, application developers, and administrators.
Users can author ES|QL queries to find specific events, perform statistical analysis, and generate visualizations. It supports a wide range of commands and functions that enable users to perform various data operations, such as filtering, aggregation, time-series analysis, and more.
The Elasticsearch Query Language (ES|QL) makes use of "pipes" (|) to manipulate and transform data in a step-by-step fashion. This approach allows users to compose a series of operations, where the output of one operation becomes the input for the next, enabling complex data transformations and analysis.
ES|QL | Elasticsearch Guide [8.11] | Elasticから引用
バージョン8.11未満のKibanaのDiscoverでは、主にKibana Query Language (KQL)を使って検索を行います。 KQLはフィルタリングを行うためのクエリ言語で、データの集約、変換、並び替えなどの機能がありません。
ES|QLの登場によってデータの集約などをDiscoverで簡単に行うことができます。
補足
以前からQuery DSLやEQL、SQLを使用することで集計を行うことはできました。 しかし、REST API経由で使用する必要があるなどGUIベースで操作できるKibanaを経由して使用するメリットがあまりありませんでした。
ES|QLの特徴
ES|QLの処理の流れは以下のようになっています。
The following example first sorts the table on @timestamp, and next limits the result set to 3 rows:
FROM sample_data | SORT @timestamp DESC | LIMIT 3
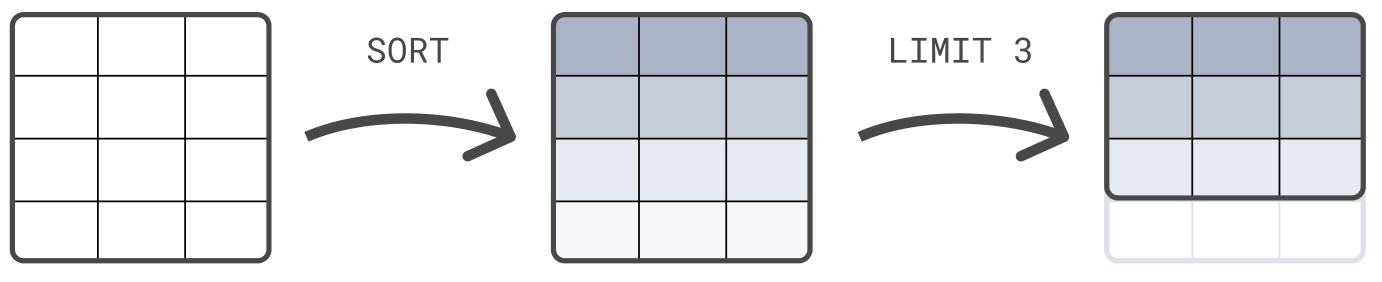
Getting started with ES|QL queries | Elasticsearch Guide [8.11] | Elasticから引用
ES|QLでは、コマンド同士をパイプ(|)で繋ぐことで次のコマンドにデータを渡します。
引用画像のようにsample_dataはまずSORTコマンドによってソートされ、その結果がLIMITコマンドに渡されます。
WHEREコマンドのように対象のデータが少なくなる処理が含まれる場合やWHEREコマンドを複数使う場合には、よりデータが減りそうな項目から先に処理することで処理時間が短くなることが期待できそうです。
ES|QLを使ってnginxのアクセスログを分析してみる
今回は、nginxのアクセスログから特定のエンドポイントの応答時間を調べます。
まずは集計の対象とするアクセスログを確認してみます。
FROM filebeat-* | WHERE event.dataset == "nginx.access" // host名はダミーです。 | WHERE host.name == "hoge" or host.name == "fuga" // urlはダミーです。 | WHERE nginx.access.url == "/hoge/fuga" | WHERE nginx.access.method == "POST" | WHERE nginx.access.response_code == "200" | KEEP nginx.* | LIMIT 10
まず、データソースはfilebeatのインデックスです。nginxのアクセスログはfilebeatによって収集されているためです。
続いて、WHEREコマンドを用いてデータをフィルタリングします。この際に、よりフィルタリング結果が少なくなりそうな項目から先にフィルタリングします。
最後に、KEEPコマンドを用いて確認したい項目(今回であればnginxに関する項目のみ)に絞り込みます。これは、SQLのSELECTに当たるコマンドです。
実行結果は以下の通りです。
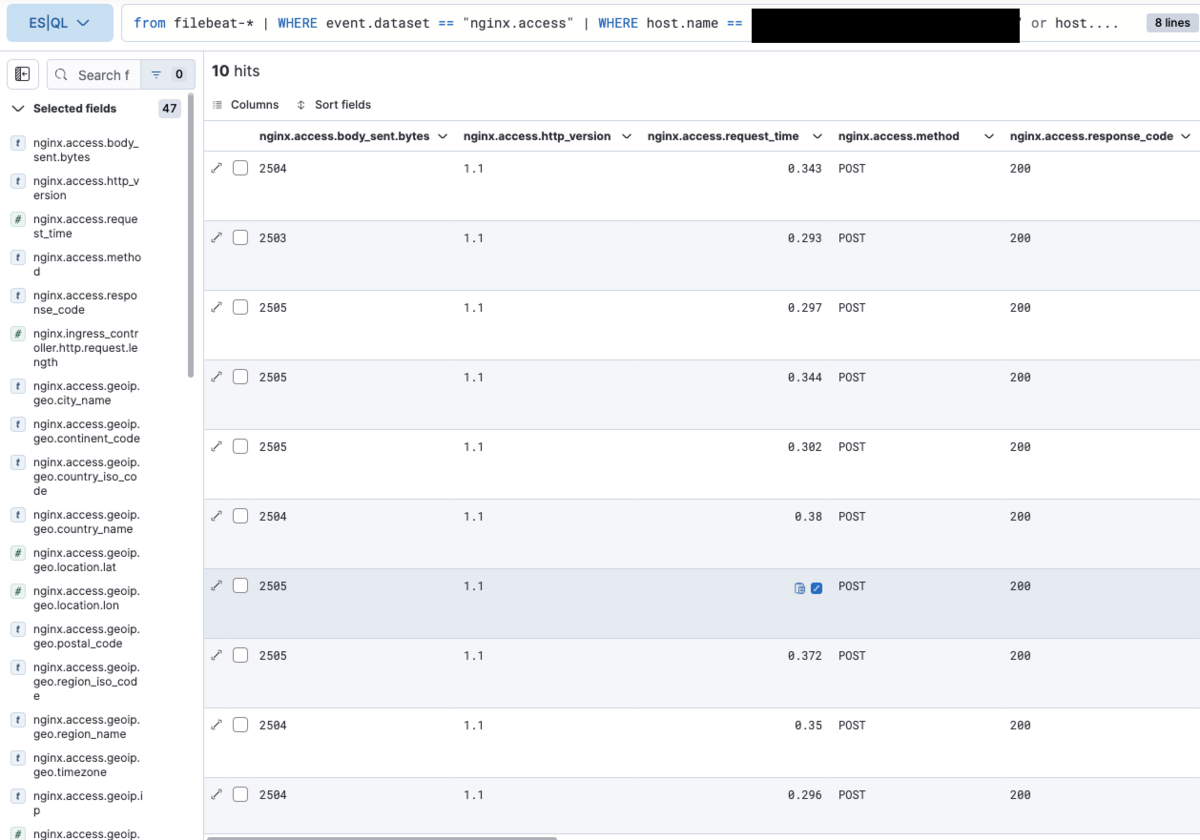
結果を確認してデータの絞り込みに問題がないことを確認したため、集計処理を行います。
FROM filebeat-*
| WHERE event.dataset == "nginx.access"
// host名はダミーです。
| WHERE host.name == "hoge" or host.name == "fuga"
// urlはダミーです。
| WHERE nginx.access.url == "/hoge/fuga"
| WHERE nginx.access.method == "POST"
| WHERE nginx.access.response_code == "200"
| STATS average = AVG(nginx.access.request_time)
, min = MIN(nginx.access.request_time)
, max = MAX(nginx.access.request_time)
, p90 = PERCENTILE(nginx.access.request_time, 90)
, p95 = PERCENTILE(nginx.access.request_time, 95)
, p99 = PERCENTILE(nginx.access.request_time, 99)
先ほどのKEEPコマンドの代わりにSTATSコマンドを用いて集計処理を行います。
このコマンドは、フィルタリングされたデータに対して、集計関数によって集計した結果を返します。
今回はnginx.access.request_timeの平均値、最小値、最大値と90, 95, 99パーセンタイル値を求めます。
実行結果は以下の通りです。
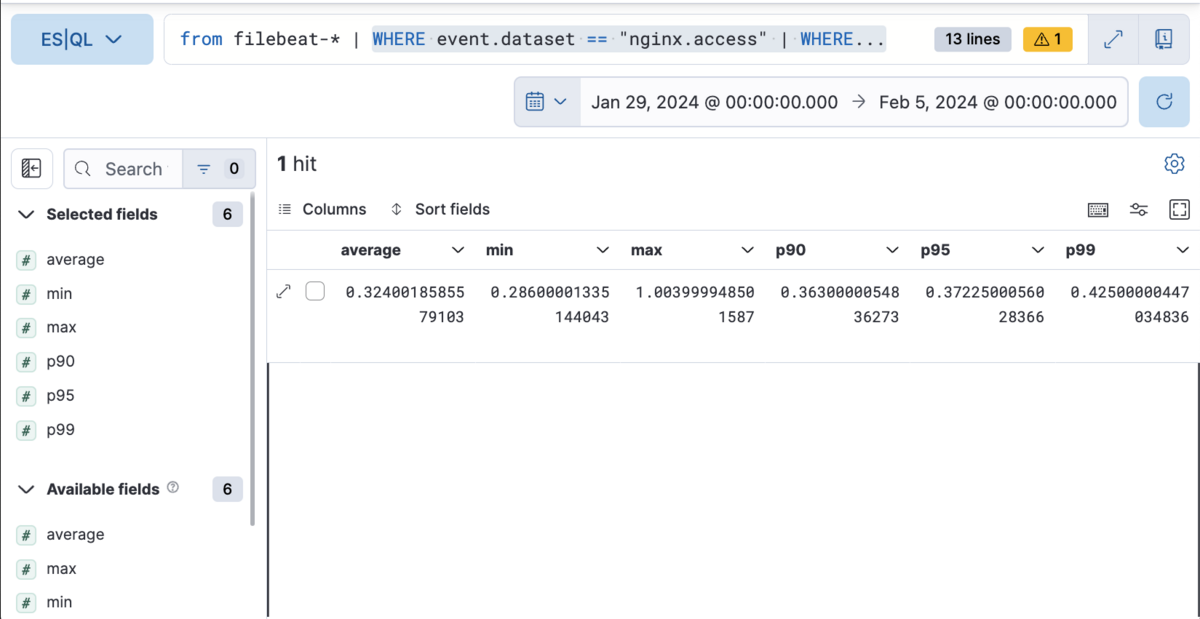
nginx.access.request_timeの平均値、最小値、最大値、90、95、99パーセンタイル値を求めることができました。
同じデータを用いても、わずかに異なる結果が得られることがあります。
ただし、nginx.access.request_timeの単位は秒になっているため数字が小さく、また小数点以下何桁も表示されており見づらいです。
そこで、単位をミリ秒となるように変換して小数点以下は丸めるようにしてみます。
FROM filebeat-*
| WHERE event.dataset == "nginx.access"
// host名はダミーです。
| WHERE host.name == "hoge" or host.name == "fuga"
// urlはダミーです。
| WHERE nginx.access.url == "/hoge/fuga"
| WHERE nginx.access.method == "POST"
| WHERE nginx.access.response_code == "200"
| STATS average = AVG(nginx.access.request_time)
, min = MIN(nginx.access.request_time)
, max = MAX(nginx.access.request_time)
, p90 = PERCENTILE(nginx.access.request_time, 90)
, p95 = PERCENTILE(nginx.access.request_time, 95)
, p99 = PERCENTILE(nginx.access.request_time, 99)
| EVAL average_ms = ROUND(average * 1000)
, min_ms = ROUND(min * 1000)
, max_ms = ROUND(max * 1000)
, p90_ms = ROUND(p90 * 1000)
, p95_ms = ROUND(p95 * 1000)
, p99_ms = ROUND(p99 * 1000)
| KEEP average_ms, min_ms, max_ms, p90_ms, p95_ms, p99_ms
先ほどの集計結果に対して、EVALコマンドを用いてミリ秒への変換と、小数点以下を丸めるようにしました。
また、STATSコマンドやEVALコマンドは新しい列を出力に追加します。そのため、KEEPコマンドを用いてEVALコマンドの計算結果のみを出力するようにしています。
※ EVALコマンド内でSTATSコマンドと同じ変数名を使うことでKEEPコマンドによる絞り込みは不要になりますが、ミリ秒であることを表現したいためKEEPコマンドを使用しました。
実行結果は以下の通りです。
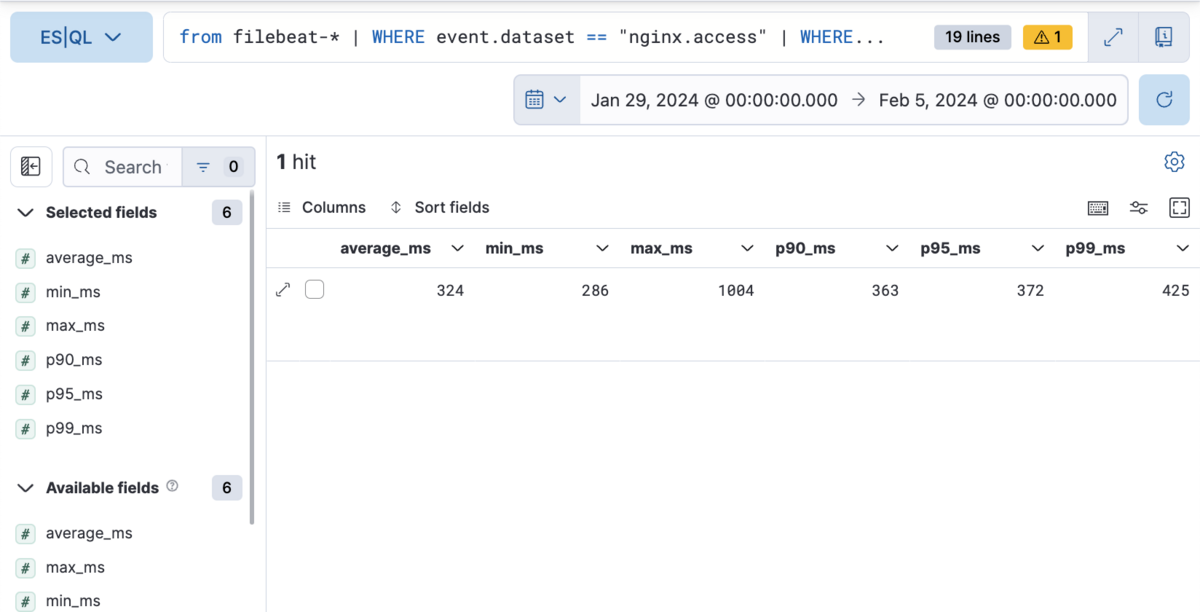
先ほどの出力と比較して、かなり分かりやすくなりました。
おわりに
今回はES|QLでの集計について試してみました。簡単に複数ログの情報を集計することができました。
障害発生時の調査など、普段から監視対象としていない項目に関して突発的に調査を行う場合にも役立てられそうです。
現在はまだテクニカルプレビューですが早くGAになることを期待したいです。
ここまでお読みいただき、誠にありがとうございます。 本内容がお役に立てれば幸いです。
参考ページ
ELK Stack = Elasticsearch、Kibana、Beats、Logstash | Elastic