

はじめに
こんにちは、アプリケーションチームの川北、大町です。
アプリケーションチームは Scala と AWS Lambda(以下 Lambda)で実装した社内ツールを全社向けに提供しており、毎日使われるものとなっています。
本ツールは「レスポンスタイムが平均6秒、最大20秒ほどかかる」という性能課題を抱えていました。 今回はカスタムランタイムへの移行と並列処理を駆使し、性能改善を実施したのでご紹介したいと思います。
社内ツールの概要
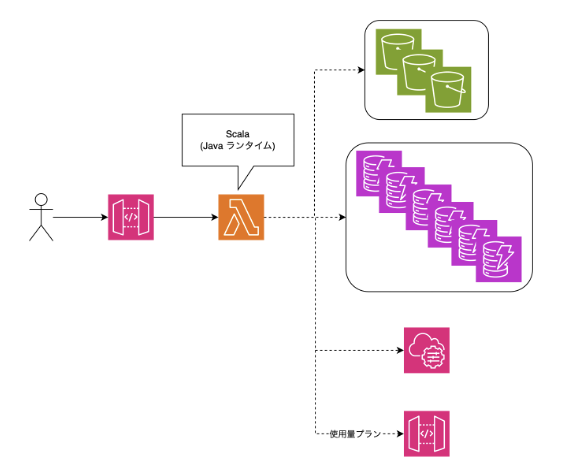
ツールの構成は以下の図の通りです。
- ユーザーからリクエストを受け取る
- Lambda が複数ストレージ・サービスから必要なデータを直列に取得
- 取得したデータを整形し、レスポンスを返す
性能課題の原因
1. コールドスタート
本ツールの Lambda は Java ランタイムであり、コールドスタート時は JVM の起動など重たい処理が行われます。そのため、起動時間は他言語のランタイムと比較して長い傾向にあります。
さて、本ツールは「散発的に実行される」という特徴があります。そのため、Lambda がコールドスタートで呼ばれる回数が多い傾向にあります。 実際、実行回数の約 50% はコールドスタートとなっていました。
2. 直列処理
先述した通り、本ツールの Lambda は複数ストレージ・サービスから必要なデータを直列に取得しているため、実行時間が長くなっています。
以下はツールの処理を再現したもので、for式の中でデータを直列に取得していることが分かります。
for { dataA <- getDataA(id = "id") dataB <- getDataB(id = "id") dataC <- getDataC(id = "id") ... ... }
しかし、これらのデータ取得処理は順序に依存していないため、直列処理は冗長です。 このため、実行時間の最適化が課題となっています。
改善方法
1. カスタムランタイム
コールドスタート時の影響を軽減するために、Java ランタイムからカスタムランタイムへと移行しました。これにより JVM を介することなく Lambda を実行できるようになりました。
結果として、Lambda の起動にかかる時間を約 1/10 に短縮することができました。
なお、カスタムランタイム上でアプリケーションを動かすために、アプリケーションコードは JAR ファイルではなく GraalVM でネイティブバイナリに変換しています。
カスタムランタイムについてはAWS Lambda カスタムランタイムを使って性能改善&コスト削減もご参照いただければと思います。
2. 並列処理
実行時間を短くするために、並列処理を導入しました。
並列処理を用いることで、データ取得処理を同時に実行し、全体の実行時間を短縮することができます。
以下は先述したツールの直列処理を並列化したものです。
import scala.concurrent.{Future, Await} import scala.concurrent.duration.Duration import scala.concurrent.ExecutionContext.Implicits.global val dataAFuture = Future { getDataA(id = "id") } val dataBFuture = Future { getDataB(id = "id") } val dataCFuture = Future { getDataC(id = "id") } for { dataA <- Await.result(dataAFuture, Duration.Inf) dataB <- Await.result(dataBFuture, Duration.Inf) dataC <- Await.result(dataCFuture, Duration.Inf) } yield (...)
このコードでは、Futureを使用してデータ取得処理を並列に実行しています。Futureは非同期処理を表現するためのScalaの標準ライブラリで、ExecutionContextを用いて並列に実行されます。
具体的には、以下の手順で並列処理を実現しています。
Futureを用いて、getDataA、getDataB、getDataCの各処理を非同期に実行します。Await.resultを使用して、各Futureの結果を待ちます。- 最後に、
for式を用いて各データを取得し、結果をまとめます。
※ExecutionContext・Durationの値は処理に合わせて調整します。
この方法によりデータ取得処理が並列に実行されるため、全体の実行時間を大幅に短縮することができます。 本ツールでは合計 7 つのストレージ・サービスからデータを取得していたため、結果としてデータ取得処理の実行時間を約 1/7 に短縮することができました。
改善結果
改善効果は以下の図の通りです。
平均実行時間が改善前と比較して 約 1/6 になり、1 秒かからないところまで改善できました。
コールドスタートに絞った場合も、実行時間を 1/6 に短縮できました。


おわりに
本記事では、カスタムランタイムと並列処理を駆使した性能改善について紹介しました。 ツールを使ってくださっている方から「とても早くなってびっくりです」という声もいただけました。
カスタムランタイムや並列処理によって改善が見込まれる Lambda が社内にはまだまだ存在するので、今後も改善を進めていきたいと思います。
ここまでお読みいただきありがとうございました。
本内容がお役に立てれば幸いです。