

はじめに
こんにちは、アプリケーションチームの小西です。
アプリケーションチームではさまざまなAWSサービスを利用しており、Amazon EC2(以下EC2)もその1つです。今回、EC2のAuto Scaling グループ(以下ASG)を使用してアプリケーションをデプロイする際に、EC2のインスタンスが想定通りに入れ替わらない課題が発生したため、解決方法を調べました。その内容と、対応時に困ったことについて共有いたします。
EC2のインスタンスが想定通りに入れ替わらない課題
Auto Scaling グループとは
まず、ASGの基本的な概念について簡単におさらいします。ASGは、希望するキャパシティに応じてEC2インスタンスの数を自動的に調整する機能を提供します。起動テンプレートを指定し、同じ設定のインスタンスをスケーリングするために使用されます。
スケーリングポリシーやスケジュールでアクションを設定することで、インスタンス数を条件に応じて増減できます。
作業していた内容
EC2で起動しているアプリケーションの更新作業を行っておりました。 最新のアプリケーションファイルはインスタンス起動時にS3から取得されるため、ASGを利用してインスタンスの入れ替えを行います。 具体的な手順は以下の通りです。
# 希望するインスタンス数を増やす aws autoscaling update-auto-scaling-group --auto-scaling-group-name xxx-auto-scaling-group --max-size 4 --min-size 4 --desired-capacity 4 # Auto Scalingによるインスタンス起動が完了するまで待つ # 希望するインスタンス数を減らす aws autoscaling update-auto-scaling-group --auto-scaling-group-name xxx-auto-scaling-group --max-size 2 --min-size 2 --desired-capacity 2
発生した課題
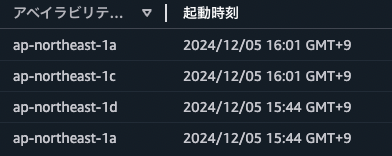
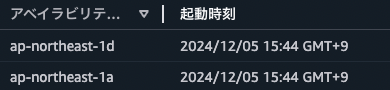
インスタンス数を減らしたときに、内部で動作しているアプリケーションが古い、先に起動したインスタンスが終了する想定でした。しかし、実際には起動したばかりの、後(16:01)に起動したインスタンスが終了し、先(15:44)に起動したインスタンスが残りました。
原因
上記の事象が発生した原因は、ASGの設定にありました。ASGはインスタンスを終了するときに終了ポリシー(termination policy)にしたがってどのインスタンスを終了するか選択します。この設定が「Default」になっておりました。
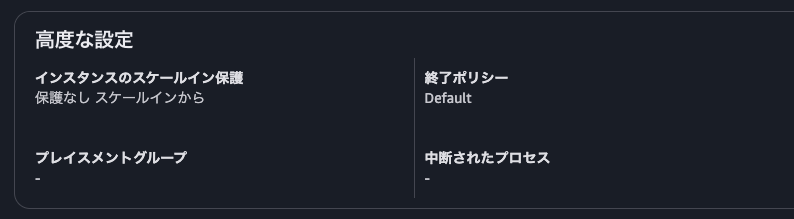
AWSのドキュメントにも記載されている通り、「Default」ポリシーの場合、下記の順に条件を適用して終了するインスタンスを決定します。
- 終了することでアベイラビリティゾーン(AZ)間で起動している数の均衡がとれるインスタンス
- 起動設定(起動テンプレートの古いバージョンのような機能)を使用して起動されたインスタンス
- 起動テンプレートを使用して起動されたインスタンスのうち、使用されているテンプレートがより古いインスタンス
- 次の課金時間がもっとも先にくるインスタンス
- ランダムなインスタンス
今回は、AZ間での均衡は影響しておらず、すべて同じ起動テンプレートを使用していたため、4、5の条件で判断されておりました。そのため、インスタンス数を減らしたタイミングでは新しいインスタンスの方が課金時間が近く、新しいインスタンスが終了してしまいました。
対策
対策としては、(ドキュメントの通り)ASGの終了ポリシー設定を変更すればよいです。今回は起動時間がより古いインスタンスを終了すればよいため、「OldestInstance」ポリシーを使用します。
該当の環境ではCloudFormationを使用してASGの設定をしていたため、下記の設定を追記しました。
Resources: AutoScalingGroup: Type: AWS::AutoScaling::AutoScalingGroup Properties: TerminationPolicies: - OldestInstance
上記により、必ず起動時間が古いインスタンスが選択されるようになり、確実にアプリケーションの更新が行えるようになりました。
調査中に困った点
事象が再現しない
ここまでの内容だと「AWSのドキュメント通りやったらできた」だけですが、実際には調査中に少しだけ困ったことがあったため、そちらについても共有します。上記事象の原因と対策自体はインターネット検索ですぐに分かったのですが、動かしてみると私の想定と違う部分がありました。
課題の原因が特定できたため、「再現確認→修正→修正確認」という手順で進めようとしたのですが、再現確認時になかなか再現できないという問題が発生しました。EC2インスタンス(該当環境はLinuxインスタンスでした)の課金時間については、Amazon EC2 料金表を参照すると1秒ごとの課金のため、インスタンス数を減らしたときにどれが課金時間が先にくるかは実質ランダムに近いと考えました。そのため何度か「作業していた内容」の手順を繰り返してみたのですが、毎回古いインスタンスが終了される(=そもそも課題となった事象が発生しない)ということが起きました。再現させることができければ修正確認ができないため、「理論上は直っている(はず)」という歯切れの悪い状況になってしまいます。
原因の調査
すぐに再現させることができなかったため、一度作業を中断し、時間をおいてから調査を再開しました。すると今度はあっさりと再現し、「これはインスタンス数を増やした時間と減らした時間の間隔に何か要因がある」と考えました。そのため、さまざまな間隔でインスタンスの増減を繰り返してみました。
その結果、「インスタンスの終了判定には起動から1時間単位の時間が使用される」ということがわかりました。
※AWSにも問い合わせ、現在はこの通りの仕様となっていることが確認できました。
たとえばインスタンスの起動日時が下記のような場合を想定します。
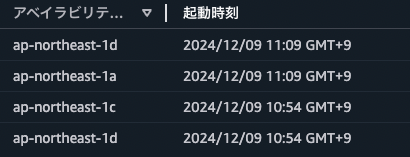
このとき、インスタンス数を減らした時刻によって、下記の動作になります。
| インスタンス数を減らした時刻 | 動作 |
|---|---|
| x:00〜x:08 | 11:09の新しいインスタンスが終了 (次のx:09の方が次のx:54より先にくるため) |
| x:09〜x:53 | 10:54の古いインスタンスが終了 (次のx:54の方が次のx:09より先にくるため) |
| x:54〜x:59 | 11:09の新しいインスタンスが終了 (次のx:09の方が次のx:54より先にくるため) |
推測ですが、以前はLinuxインスタンスの課金時間も1時間単位であったため、その時と動作が変わっていないのではないかと考えています。(1秒単位の課金時間だとどちらを終了しても金額が大きく変わることもないため、妥当な動作だと思います)
今回作業していたような手順(インスタンスを増やしてすぐ減らす)の場合、作業時間は5分程度でしたので、そのタイミングでちょうど古いインスタンスの起動した分(上記例だと54分)を超えなければ新しいインスタンスが終了する事象は発生しません。そのため、そもそもの課題検知時に私が遭遇した事象も意外と稀なものであったと考えられます。
対策
原因が判明したあとも何度か手順を繰り返し、100%同じ動作となることを確認しました。その後終了ポリシーを「OldestInstance」ポリシーに設定し、同じ手順を繰り返して今度は必ず古いインスタンスが終了するようになっていることを確認しました。この対策により、今後同様の課題が発生するリスクをなくすことができました。
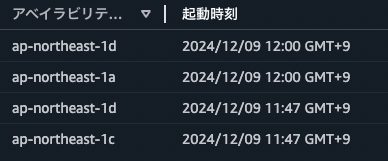
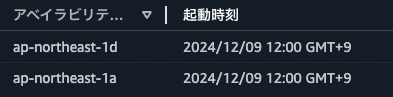
おわりに
今回の記事では、Auto Scaling グループのEC2インスタンスが終了する順番が想定と異なる課題の原因調査と対策の流れを共有させていただきました。細かい動作に関する内容ではありますが、本記事がどなたかのご参考になりましたら幸いです。
ここまでお読みいただきありがとうございました。