

はじめに
こんにちは、アプリケーションチームの小沼です。
LANSCOPE EMクラウド版(以下、EMクラウド)は現在、多くのデバイスの情報を管理しています。 取得情報の中で、IT資産情報の管理にはAWSの「Amazon OpenSearch Service(以下、OpenSearch Service)」を利用しています。
これまでの経験の中で、ある時期に「OpenSearch Service」に書き込む処理の中で429エラー(TooManyRequests)が発生するようになりました。 保存している情報の性質上、「お客様が最新の情報を確認できない」や「(最悪の場合)情報の不整合」が発生する可能性があるため、429エラーを抑える対策が求められました。
今回、管理デバイス数の増加に伴い上昇していったOpenSearch Serviceの負荷改善の取り組みについてご紹介します。
負荷状況の監視
開発チームでは、管理デバイスから送られてくる通信の状況を監視しており、
- 書き込みに失敗し、リトライ処理を行った
- 大量の通信が同時に来たため遅延が発生した
といった状況を把握しています。 今回の最適化は、突発的な不具合に起因するものではなく、毎日少しずつ増加する管理デバイス数の積み重ねによる負荷増加に対するアプローチになります。

メトリクスを見てみると、遅延の傾向が大分高くなっておりました。
さらに、OpenSearch Service に書き込みの処理を行っているLambdaのログを見てみると、
429エラー(TooManyRequests)が返ってきていることが確認でき、
管理デバイス数の増加に伴う負荷の上昇が起因しているという結論に達しました。
対策実施の要件
OpenSearch Service には、EM クラウドのIT資産情報を保存しているため、 「OpenSearch Serviceに保存している情報が一時的に見れなくなる。及び情報の不整合が発生する」といった状況をできる限り避けて実施する必要がありました。
そこで、開発チームではAWSのサポートケースも使用しながら調査進め、下記の対応を実施しました。
- EMクラウドを止めずに実行できる対応(お客様影響を出さずにすぐ実行できる対応)
- マスターノード追加
- IOPSの増加
- スループットの増加
- refresh interval の設定
- EMクラウドを一度停止させないと、実行が難しい対応
- シャードサイズの見直し
- EMクラウドのクライアントモジュールの修正
- 通信頻度の見直し
先に結論
最適化に向けての動きを時系列に記載しておりますが、先に結論をまとめます。
◯:効果あり、△:多少の効果あり、✗:ほぼ効果なし
- EMクラウドを止めずに実行できる対応(お客様影響を出さずにすぐ実行できる対応)
- マスターノード追加:△
- IOPSの増加:◯
- スループットの増加:◯
- refresh interval の設定:△
- EMクラウドを一度停止させないと、実行が難しい対応
- シャードサイズの見直し:未実施
- EMクラウドのクライアントモジュールの修正
- 通信頻度の見直し:◯
EMクラウドを止めない対策を優先して実施していきましたが、いずれも「遅延が再発する」ものばかりでした。
インフラ面の性能強化において、銀の弾丸になりうるものは無いのかもしれません。
安定して遅延解消につながったのは、クライアントモジュールの「通信頻度の見直し」です。
通信の総量を減らしているために、「それはそうだろう」となるかもしれません。
しかし、「そう」なのです。すべてのパターンにおいて通用する対応ではないですが、もし通信の総量を調整できるなら、一番確実で繰り返しの対応が不要になる方法だと思います。
対策の実施内容
対策①: マスターノード追加
まず行ったのは、マスターノードの追加です。 EMクラウドで使用しているOpenSearch Serviceでは3ノードを使用していますが、マスターノードは用意しておりませんでした。 AWSのサポートケースで429エラーの解決方法を相談し、最初に提案いただきました。 マスターノードの追加は、ブルーグリーンデプロイが可能のため、お客様影響を少なく実施が可能な対応でした。
マスターノード有効化のリリース後

対策②: IOPS 増加
続いて行ったのが、OpenSearch Service のIOPSの強化です。 マスターノードの追加だけでは遅延が収まらず、OpenSearch ServiceのメトリクスとOpenSearch Serviceの設定値の見比べを行いました。 そこで発見したのが、IOPSの不足です。 Read IOPS / Write IOPS を合計すると、スロットルするかどうかの瀬戸際でした。 IOPSの増加も、 ブルーグリーンデプロイが可能な項目です。お客様影響を少なく実施可能な対応として、すぐに実施しました。
IOPS 増加のリリース後

対策③: refresh interval の変更
すでに2回リリースを終えているため、インフラ面の性能強化に限界を感じて来ました。
そこで次に実施した対応は、refresh interval 値の変更です。
デフォルト1 秒の設定値となっており、この秒数を伸ばすことが負荷軽減に繋がります。
しかし、refresh interval を設定することの影響は、「OpenSearch Serviceへの反映が常にrefresh interval 分遅れる」になります。
AWSの推奨は60秒以上ですが、EMクラウドはデフォルトの1秒でリリースし、さらに5年以上経過している機能において、
「1秒後更新」から「60秒以上待ってから更新」は簡単に実施できる内容ではありませんでした。
そこで、責任者層への判断を仰ぎ、社内での連携を取りながら、「この秒数までなら許容できそう」というラインを出し、実施に取り掛かりました。
refresh interval 変更のリリース後

refresh interval 以外にリリース作業を行っていなかったため、AWS のサポートケースでrefresh interval の設定によって負荷が上がることがあるのかを確認したところ、 refresh interval の設定で負荷が増えることは無いと断言頂いています。
refresh interval を設定していなかったら、もっと遅延をしていたのかもしれません。
対策④: スループット 増加
refresh interval 変更のリリース後、遅延が大きくなってしまい、EMクラウドの停止を必要とする対応(シャードサイズ変更)に舵を取るべきかと悩んでいたところでした。 OpenSearch Service のメトリクスを確認すると、ThroughputThrottle は下図のように断続的に発生していました。 そこで、OpenSearch Service のスループット増加を実施しました。
当時のスループットスロットルの様子は下記でした。
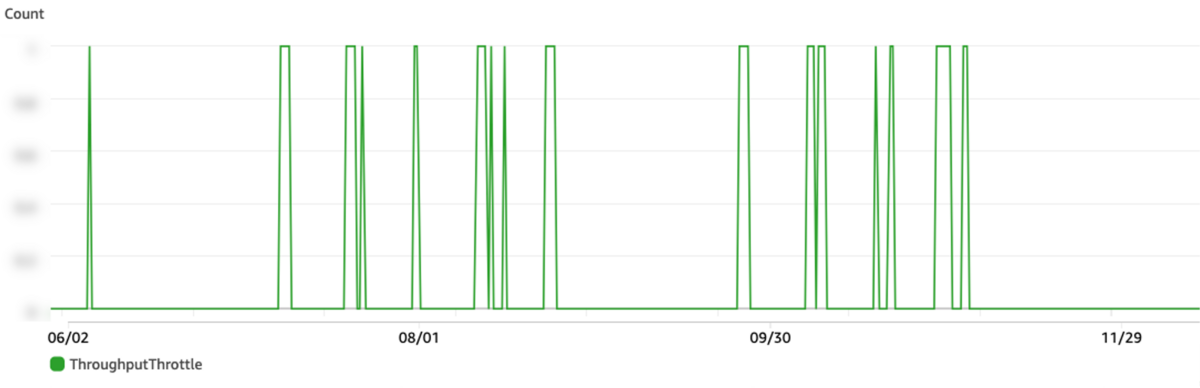
スループット増加のリリース後

対策⑤: 通信頻度見直し
EMクラウドを止めずに実施できる対応の裏で、修正を進めていました。 EMクラウドで管理できるWindows/Android/iOS/macOSはそれぞれデバイスから通信を送ります。 Windows デバイスは、EMクラウドの「最新情報を取得」の機能に対応しておらず、Android/iOS/macOSと比較して、高頻度に通信を送っておりました。 今回、OpenSearch Serviceの負荷軽減を目指して、Windows デバイスの「最新情報を取得」の機能に対応するとともに、通信頻度を他OSと合わせることで、 負荷軽減に取り組みました。

スループットの増加後、ほんの少し発生していた遅延が、通信頻度の見直しにより、ほぼ0となりました。
通信の総量を変更できるパターンは多くないかもしれません。
しかし、可能であるなら一番の近道になると思います。
なにより、短期間に繰り返しメンテを必要としない手段となり得るので、次のロードマップ開発に集中しやすい体制を作れると思います。
対策⑥: シャードサイズ見直し
こちらは、EMクラウドでは未実施の内容となります。
しかし、AWSのサポートケースや、担当SAさんからのコメントでは、一番推される内容となっています。
通信頻度の見直しにより、遅延がほぼ0となったため、優先度は落ちつつありますが、いずれやらなければならない対応と認識しており、計画中です。
おわりに
EMクラウドにおけるOpenSearch Serviceの負荷改善の様子を時系列で紹介させていただきました。
OpenSearch Serviceの負荷が高く困っている方の助けになれば幸いです。