

こんにちは!インフラチームの蓑星です。
エムオーテックスでは LANSCOPE クラウド版の開発において、製品コードに Scala、スクリプトなどに Python を利用しています。 今回は使いこなすと Python の処理を爆速!にできる、「並行処理」についてご紹介。
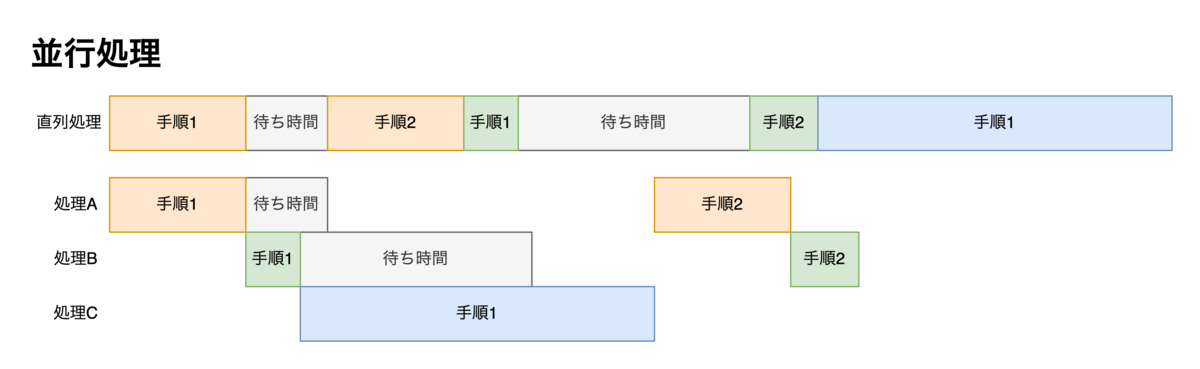
並行処理? 並列処理?
実行したい一連のプログラムを「処理」、処理を進めるために完了しなければならないことを「手順」とします。 また、手順と手順の間には、ディスクの読み書きやネットワークへのアクセスなどの「待ち時間」が発生する可能性があるものとします。

プログラミングにおける「並行処理」とは、複数の処理を同時に実行することで高速・軽量化を図ることを指します。 その中でも、複数のコアを使って複数の手順を同時に実行することを「並列処理」と言います。
並列処理でない並行処理は、待ち時間の間に他の処理の手順を実行していきます。以後はこれを狭義の並行処理として並列処理と区別して説明します。
人間に例えると、
- 洗濯機を回している間に床掃除をする → 並行処理
- 友達を呼んで床掃除をしてもらっている間に洗濯をする → 並列処理
のようなものです。 洗濯機のスイッチを押してから洗濯機が止まるまでの時間が待ち時間ですね。
Python での実現方法
マルチスレッド
並行処理は、ある瞬間では同時に手順を実行しないため、シングルコア CPU でも実行が可能です。 手順の間に待ち時間が発生しているときに他処理の手順に移ることで、ムダな待ち時間を削減し結果的な処理時間が短縮される仕組みになっています。
複数回の API の呼び出しや大容量のデータ読み書きなどの待ち時間が多い処理に効果的です。
Python で並行処理を実現する方法の一つとして、ThreadPoolExecutor() によるマルチスレッド処理が存在します。
from concurrent.futures import ThreadPoolExecutor ~~~ with ThreadPoolExecutor(max_workers=10) as thread: future = thread.submit(func, *args, **kwargs) future = thread.map(func, *iter)
map() はメソッド引数をイテレータで渡すときに利用します。返り値もジェネレータになります。
max_workers: 最大同時実行数 func: 同時実行したいメソッド args, kwargs: メソッドの引数 iter: メソッドの引数(イテレータ)
マルチプロセス
並列処理は、複数の CPU コアに処理を分散させて同時に複数の手順を実行することで全体の処理時間を短縮します。 当然、シングルコア CPU の場合同時実行することはできません。
複雑なデータ検索やファイルの変換などの、計算量が大きく分割しても結果に影響を与えない処理に効果的です。

Python で並列実行を実現する方法の一つとして、ProcessPoolExecutor によるマルチプロセス処理が存在します。
from concurrent.futures import ProcessPoolExecutor ~~~ with ProcessPoolExecutor(max_workers=10) as process: future = process.submit(func, *args, **kwargs) future = process.map(func, *iter, chunk_size=10)
chunk_size: 1プロセスあたりに分割する実行数
利用例
並行処理
LANSCOPE クラウド版はプラットフォームに AWS を採用しているため、AWS とのデータのやりとりが非常に多くなります。 その中でも、データのやりとりが多い代表として、ストレージサービスの S3 へのデータ読み書きがあります。
boto3 というライブラリを使って S3 に用意されている API にアクセスを行います。その際にレスポンスの待ち時間が発生するため、前述したマルチスレッドを採用して高速化を図ります。
以下は 100 個のファイルを S3 へアップロードするスクリプトです。 並行処理化していない状態です。
import boto3 from pathlib import Path ~~~ def upload(): p = Path("files") for strpath in (str(filepath) for filepath in p.glob("*.txt")): bucket.upload_file(strpath, strpath.split("/")[-1]) if __name__ == "__main__": upload()
このスクリプトの実行時間は 159 秒でした。
❯ time python s3_upload_serial.py python s3_upload_serial.py 8.90s user 4.43s system 8% cpu 2:39.04 total
upload() を並行処理に書き換えます。
from concurrent.futures import ThreadPoolExecutor ~~~ def _upload_internal(filepath: str): bucket.upload_file(filepath, filepath.split("/")[-1]) def upload(): p = Path("files") with ThreadPoolExecutor(max_workers=5) as thread: thread.map(_upload_internal, (str(filepath) for filepath in p.glob("*.txt"))) ~~~
書き換えた後の実行時間は、131 秒でした。
❯ time python s3_upload_concurrent.py python s3_upload_concurrent.py 10.13s user 4.96s system 11% cpu 2:10.80 total
今回の例では、実行時間を 28 秒(18 %)短縮できました!
並列処理
お客様が利用するデバイスから資産情報などを取得しているため、扱うデータには個人情報なども含まれます。 セキュリティ的観点から、暗号化した状態で保存しているデータも数多く存在します。
暗号化の処理はプログラム内で完結するのですが、計算量が大きくファイル 1 個ずつ処理すると時間がかかります。 そこで、前述したマルチプロセスを採用して、 10 個ずつに分けたファイルを複数同時に暗号化処理へ通すことで高速化を図ります。
以下は 100 個のファイルを AES256 暗号化するスクリプトです。 並列処理化していない状態です。
from pathlib import Path from Crypto.Cipher import AES from Crypto.Hash import SHA256 from Crypto import Random def _create_aes(password: str, initial_vector: bytes): sha = SHA256.new() sha.update(password.encode()) key = sha.digest() return AES.new(key, AES.MODE_CFB, initial_vector) def encrypt(filepath: str, password: str): with open(filepath, "r") as readfile: data = readfile.read() initial_vector = Random.new().read(AES.block_size) return initial_vector + _create_aes(password, initial_vector).encrypt( data.encode("utf-8") ) def encryption(): p = Path("files") for strpath in (str(filepath) for filepath in p.glob("*.txt")): encripted = encrypt(strpath, "password") with open(f"encrypted_files/{strpath.split('/')[-1]}", "wb") as writefile: writefile.write(encripted) if __name__ == "__main__": encryption()
このスクリプトの実行時間は 111 秒でした。
❯ time python aes256_encryption_serial.py python aes256_encryption_serial.py 62.86s user 3.78s system 60% cpu 1:50.65 total
encryption() を並列処理に書き換えます。
from concurrent.futures import ProcessPoolExecutor ~~~ def encryption(): p = Path("files") with ProcessPoolExecutor(max_workers=5) as process: for strpath in (str(filepath) for filepath in p.glob("*.txt")): encripted = process.submit(encrypt, strpath, "password") with open(f"encrypted_files/{strpath.split('/')[-1]}", "wb") as writefile: writefile.write(encripted.result()) ~~~
書き換えた後の実行時間は、67 秒でした。
❯ time python aes256_encryption_parallel.py python aes256_encryption_parallel.py 48.61s user 6.82s system 82% cpu 1:07.43 total
今回の例では、実行時間を 44 秒(40 %)短縮できました!!
まとめ
実行時間を比較してみて、特に並列処理はかなり大きな短縮になって自分でも驚きました。
並行処理化する内容や実行環境によって、並行・並列どちらがより効果的か、どれだけの短縮になるか変わってきます。 どう使い分けてより速いプログラムに仕上げられるかが腕の見せどころですね!
Python の並行処理には、今回ご紹介した「マルチスレッド」の他に、「イベントループ」という仕組みも存在します。そちらに関してもいつかご紹介したいと考えています…!